ML Model Deployment
ML in production vs. ML in research
These are important for ML in production than in research:
- stakeholder involvement
- computational priority
- the properties of data used
- the gravity of fairness issues
- the requirements for interpretability
Model Serving
- key components
- a model
- an interpreter
- input data
- important metrics:
- latency = the time it takes from receiving a quest to returning the result
- throughput/successful request rate = how many queries are processed within a specific period of time
- cost: for compute resources (CPU, etc.)
- minimizing latency and maximizing throughput will increase cost, which can be balanced by
- reducing costs by GPU sharing
- multi-model serving
- optimizing models used for inference
Deployment procedures
- ML model deploy in production
- Monitor & maintain system (ML System Monitoring and Continual learning)
Deployment approaches
- Cloud-based deployment
- deploy a model on a cloud service provider like AWS or GCP. You can use services like AWS Elastic Beanstalk, Google Kubernetes Engine, or Azure Machine Learning to deploy and manage your model.
- Containerization
- containerize a model using tools like Docker and deploy it on a container orchestration platform like Kubernetes.
- Server-based deployment
- deploy a model on a dedicated server or a cluster of servers, such as using TensorFlow Serving. The servers run an application that exposes an API endpoint (REST or gRPC), which can be accessed by client applications to make predictions on the model.
- Serverless deployment
- deploy a model as a serverless function using platforms like AWS Lambda or Google Cloud Functions.
- Mobile deployment
- deploy a model on the mobile device itself, using tools like Core ML for iOS or TensorFlow Lite for Android.
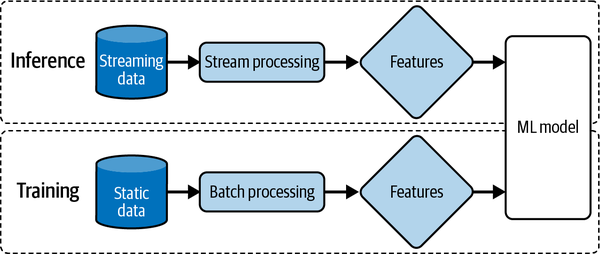
Batch Prediction Versus Online Prediction
What are they
-
batch prediction = when predictions are generated periodically or whenever triggered. The predictions are stored somewhere, such as in SQL tables or an in-memory database, and retrieved as needed.
-
online/real-time prediction = when predictions are generated and returned as soon as requests for these predictions arrive
| Batch prediction (asynchronous) | Online prediction (synchronous) | |
|---|---|---|
| Frequency | Periodical, such as every four hours | As soon as requests come |
| Useful for | Processing accumulated data when you don’t need immediate results (such as recommender systems) | When predictions are needed as soon as a data sample is generated (such as fraud detection) |
| Optimized for | High throughput | Low latency |
| Cost | Pay for resources while endpoint is running | Pay for resources for the duration of the batch job |
Unifying Batch Pipeline and Streaming Pipeline
Nowadays, the two pipelines can be unified by having two teams: the ML team maintains the batch pipeline for training while the deployment team maintains the stream pipeline for inference
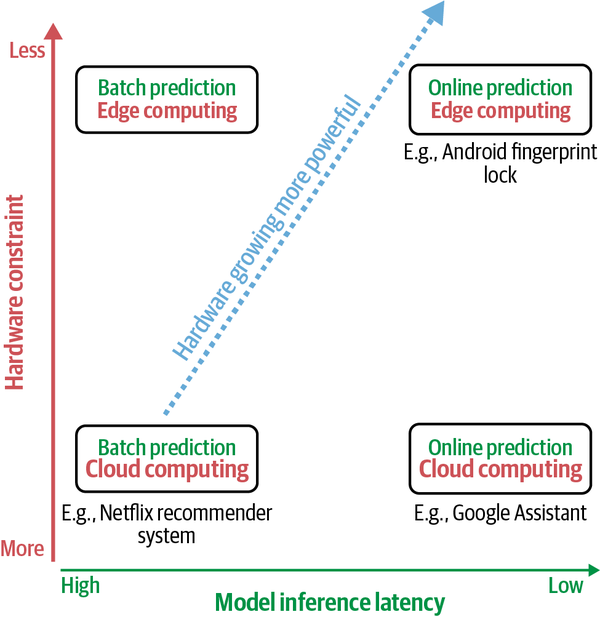
How to accelerate ML model inference
There are three main approaches to reduce its inference latency:
- make it do inference faster: model optimization
- locally
- Vectorization
- Parallelization: Given an input array (or n-dimensional array), divide it into different, independent work chunks, and do the operation on each chunk individually
- Loop tiling: Change the data accessing order in a loop to leverage hardware’s memory layout and cache
- Operator fusion: Fuse multiple operators into one to avoid redundant memory access
- globally
- locally
- make the model smaller: model compression
- low-rank factorization
- replace high-dimensional tensors with lower-dimensional tensors
- knowledge distillation
- a method in which a small model (student) is trained to mimic a larger model or ensemble of models (teacher)
- pruning
- originally for decision trees (Decision Tree & Random Forest#^4c01d0)
- now also mean reducing the extra parameters in neural networks
- quantization
- reduces a model’s size by using fewer bits to represent its parameters. e.g representing a float number using 32 bits instead of 16 bits
- most general and commonly used model compression method
- low-rank factorization
- make the hardware it’s deployed on run faster: ML on the Cloud and on the Edge
- On the cloud = a large chunk of computation is done on the cloud, either public clouds or private clouds
- On the edge = a large chunk of computation is done on consumer devices
- online and on-the-edge ML models need powerful hardware
Example Workflow for Deploying a Production Machine Learning Model
- Set Up a Secure AWS Environment
- Tools: AWS Identity and Access Management (IAM), Amazon SageMaker
- Define and manage security using IAM policies.
- Data Analysis and Preparation
- Model Training and Hyperparameter Tuning
- Tools: Amazon SageMaker, GPU instances
- Set up hyperparameter tuning and perform multi-GPU instance training.
- Model Evaluation
- Deploy Model to AWS
- Tools: AWS API Gateway, AWS Lambda (AWS for Data Science#^94aba2)
- Deploy the trained model using AWS API Gateway and Lambda functions, ensuring access via REST API.
- Test the API
- Tools: Postman
- Verify API functionality by sending test requests.
- Secure and Optimize Deployment
- Tools: AWS API Gateway, Lambda, AutoScaling
- Secure API endpoints (IP whitelisting) and set up auto-scaling to handle traffic efficiently.
- Build and Deploy Web Application
- Tools: React.js, Node.js, Express.js, MongoDB
- Develop a MERN (MongoDB, Express, React, Node.js) web app that interacts with the AWS API.
- Host the Application
- Tools: DigitalOcean
- Deploy the web app to a cloud service like DigitalOcean.
- Monitor and Maintain
- Tools: Amazon CloudWatch
- Monitor performance with CloudWatch logs and manage Lambda concurrency for optimization.